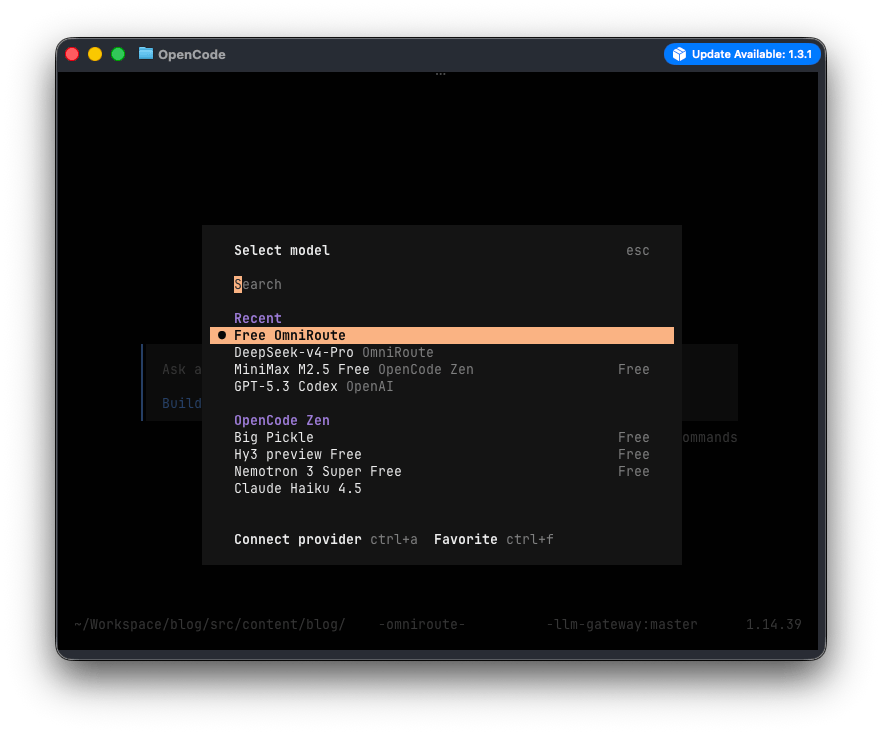
使用 OmniRoute 建置自己的 LLM Gateway
在非工作情況下,因為主要都是處理 OpenSource 相關的開發,所以我會使用一些免費的 LLM 作為輔助,但是不同家廠商提供的 LLM 節點都不一樣,這個用完換下一個要切來切去很麻煩,為了解決這種問題我們就需要架設自己的 LLM Gateway 來作為統一的節點使用。
注意: 使用免費 LLM 的代價就是資料可能會被提供作為學習使用,請注意自己提供的資訊
免費 LLM 哪裡來?
一般來說,我們可以使用 openrouter 的 免費的模型 , 但除了他們以外, opencode 也有一些免費的模型,在 free-llm-api-resources 這專案上面列了非常多驗證過並且確認可以讓個人有免費模型可以使用的服務。
我自己常用的還有:
- CereBras: 今年將要 IPO 的新創,使用 email 註冊不需要綁信用卡即有免費額度可以使用
- Kiro AI: Amazon 提供的 kiro 開發環境的節點,可以使用一些知名的付費模型 (ex: claude/sonnet 4.5)
- Nvidia NIM: Nvidia 提供的免費大模型節點,需要綁定手機,不需要綁信用卡
架設 llm gateway 有哪些選項
要自行架設 llm gateway,最常見的選項就是使用 llmlite 來建立自己的 gateway,你可以在 simpleproxy 一文知道如何透過 llmlite 來建立自己簡單的 llm gateway,由於這不是本篇文章的重點,所以就不贅述。
除了 llmlite 外,我自行測試過蠻喜歡的有 manifest、bifrost 等不同用途的程式,但是不選用的原因是因為他們沒有達到我期望的需求。
我的考量
雖然上面這些選項都蠻方便的,但是身為一個懶人,我會希望我的 llm gatway 同時能告訴我哪些地方有 free tier 可以使用,我可以用很懶惰的方式設定好並建置我的節點,因此在做選擇時候我列了以下這些清單來做決定:
- 需要有 WebUI 可以設定
- 能告訴我一些 free tier provider 這樣我不用自己找
- 可以接上本地端的 custom llm provider, 比如 ollama, lm-studio
- 可以做出類似 openrouter/free 這樣的 model 節點 (自動並切換不同 model)
最終挑了一些選項後,我選擇了 OmniRoute 作為我自己 llm gateway 的選擇
為何不選擇 9router
其實 OmniRoute 是 9router 的 fork, 我選擇他是因為他內建可以接上的 llm provider 更多,不然他們介面和功能都非常相似的,因此選擇 9router 也是一樣的。
研究一下 OmniRoute (b75b52) 和 9router (1686ad) 的程式碼,這些是我比較注重的不同點:
privider 數量
OmniRoute 支援 165+ 個 Provider(含 Bedrock、watsonx、Oracle OCI、SAP、Databricks 等企業級,而 9router 則支援約 78 個
雖然我們窮窮的人不會用到那麼多 provider, 可是選項比較多比較開心啊 :)
token 節省機制
9router 會先攔截使用者對於工具的輸入 (git, ls ...etc) 然後透過 RTK Token Saver 去將訊息減少後,再提供給 llm provider ,藉由這樣減少 token 的使用量,除此之外他還可以搭配 Caveman 這種語意壓縮技術來將內容進行上下文壓縮後再提供給 llm provider, 因此你傳送給 9router 的資料會先經過一些程式處理後才傳送給對應的 provider:
sequenceDiagram
participant User as 使用者
participant 9router as 9router 閘道
participant RTK as RTK Token Saver
participant Caveman as Caveman
participant LLM as LLM 提供者
User->>9router: 發送請求(含工具輸出)<br/>(git diff, ls, grep, ...)
9router->>RTK: 轉送請求主體
RTK->>RTK: 自動偵測內容類型<br/>(git-diff, grep, ls, tree, find, ...)
RTK->>RTK: 套用壓縮<br/>(hunk 截斷、去重、截短、每檔案行數上限)
RTK-->>9router: 返回壓縮後的請求主體<br/>[RTK] saved 12345B / 56789B (21.7%)
alt Caveman 已啟用 (lite / full / ultra)
9router->>Caveman: 注入精簡指令
Caveman->>Caveman: 選擇強度等級<br/>(lite: ~50%, full: ~65%, ultra: ~87%)
Caveman-->>9router: 已插入 caveman 指令的 system prompt
end
9router->>LLM: 發送壓縮後的請求<br/>(輸入 token 減少 60-90%)
LLM-->>9router: 返回回應<br/>(若 Caveman 啟用則輸出 token 減少 65-87%)
9router-->>User: 返回回應
OmniRoute 除了提供 RTK Token Saver 外,他還會在傳送請求前預先檢查使用者是否爆掉預算,並設計了另外設計一套 5 級壓縮管線(off → lite → standard → aggressive → ultra)機制並搭配 Caveman 進行壓縮,整個流程相對複雜許多
sequenceDiagram
participant User as 使用者
participant OmniRoute as OmniRoute 閘道
participant Policy as 政策引擎
participant Idem as 冪等層
participant Cache as 快取層<br/>(語義 + 簽名 + 推理)
participant Compress as 壓縮管線
participant Think as 思考預算
participant Router as 成本最佳化路由器
participant LLM as LLM 提供者
User->>OmniRoute: 發送請求(含工具輸出)
Note over OmniRoute,Policy: 階段 1:請求前檢查
OmniRoute->>Policy: 評估請求
Policy->>Policy: 檢查預算上限<br/>(日 / 週 / 月)
Policy->>Policy: 檢查配額預檢<br/>(跳過已耗盡的帳戶)
Policy->>Policy: 檢查鎖定政策
alt 預算超支或配額耗盡
Policy-->>OmniRoute: 阻擋請求 (402 / 429)
OmniRoute-->>User: 預算超支 / 配額耗盡
end
Note over OmniRoute,Idem: 階段 2:冪等去重
OmniRoute->>Idem: 檢查 Idempotency-Key / X-Request-Id
alt 5 秒內的重複請求
Idem-->>OmniRoute: 返回已快取的回應
OmniRoute-->>User: 快取回應(0 token 消耗)
end
Note over OmniRoute,Cache: 階段 3:多層快取查詢
OmniRoute->>Cache: 檢查語義快取<br/>(temperature=0, SHA-256 簽名)
alt 語義快取命中
Cache-->>OmniRoute: 返回已快取的回應<br/>[X-OmniRoute-Cache: HIT]
OmniRoute-->>User: 快取回應(0 token 消耗)
end
OmniRoute->>Cache: 檢查簽名快取<br/>(已學習的 XML 思考標籤)
Cache-->>OmniRoute: 套用已快取的簽名
OmniRoute->>Cache: 檢查推理重播快取<br/>(DeepSeek / OpenCode / QwQ)
Cache-->>OmniRoute: 套用已快取的推理內容
Note over OmniRoute,Compress: 階段 4:提示壓縮
OmniRoute->>Compress: 選擇壓縮策略<br/>(off / lite / standard / aggressive / ultra)
Compress->>Compress: 檢查快取感知降級<br/>(若存在 cache_control 則保留)
Compress->>Compress: 套用所選技術
alt Lite 模式
Compress->>Compress: 空白折疊 + 系統提示去重<br/>+ 工具結果截短 + 冗餘移除
else Standard (Caveman) 模式
Compress->>Compress: 30+ 規則型模式<br/>保留程式碼區塊與 URL
else Aggressive 模式
Compress->>Compress: 摘要化 + 工具結果壓縮<br/>+ 漸進式老化分層
else Ultra 模式
Compress->>Compress: 啟發式 token 修剪<br/>+ 可選的本地 SLM 回退
end
Compress-->>OmniRoute: 返回壓縮後的請求主體
Note over OmniRoute,Think: 階段 5:思考預算控制
OmniRoute->>Think: 套用思考預算
alt AUTO 模式
Think->>Think: 移除思考設定,由提供者決定
else ADAPTIVE 模式
Think->>Think: 依請求複雜度縮放預算<br/>(訊息數、工具數、最後訊息長度)
else CUSTOM 模式
Think->>Think: 設定固定 token 預算
else PASSTHROUGH 模式
Think->>Think: 原樣傳遞
end
Think-->>OmniRoute: 調整後的思考 token
Note over OmniRoute,Router: 階段 6:成本最佳化路由
OmniRoute->>Router: 選擇提供者與模型
Router->>Router: 按價格排序提供者(最便宜優先)
Router->>Router: 套用任務感知路由<br/>(推理 → 專業模型, 程式碼 → Cursor)
alt 選定的提供者失敗
Router->>Router: 模型家族回退<br/>(GPT-4 → GPT-4o, Claude Opus → Sonnet)
Router->>Router: 緊急回退至免費提供者
end
Router-->>OmniRoute: 選定:最便宜的可用提供者
Note over OmniRoute,LLM: 階段 7:附帶 cache_control 發送
OmniRoute->>OmniRoute: cache_control 政策決策<br/>(依提供者相容性決定保留或移除)
OmniRoute->>LLM: 發送壓縮、預算控管、路由後的請求
LLM-->>OmniRoute: 返回回應
Note over OmniRoute: 階段 8:後處理
OmniRoute->>Cache: 將回應存入語義快取<br/>(僅 temperature=0)
OmniRoute->>Cache: 學習新的簽名模式
OmniRoute->>Cache: 儲存推理內容以供重播
OmniRoute->>Policy: 記錄支出至預算
OmniRoute->>Policy: 更新配額快取
OmniRoute-->>User: 返回回應<br/>[X-OmniRoute-Tokens-In/Out, X-OmniRoute-Cache, X-OmniRoute-Response-Cost]
如何架設 OmniRoute
要架設 OmniRoute ,最簡單的方式就是直接使用 npm 安裝現成的程式
npm install -g omniroute
omniroute他會將設定檔案建立到 ~/.omniroute 資料夾內,裡面有這些東西
db_backups storage.sqlite storage.sqlite-shm storage.sqlite-wal由於預設他連線 custom endpoint 是不允許使用 private ip 的連線方式,因此我們可以建立 ~/.omniroute/.env 檔案,加入以下這一行後再重新啟動 omniroute , 這樣他就可以順利連線本地端的 OpenAI compatible llm provider
# Allow provider URLs pointing to private/local networks (localhost, 192.168.x.x, etc.).
# REQUIRED for self-hosted providers: LM Studio, Ollama, vLLM, Llamafile, Triton, etc.
# Used by: src/shared/network/outboundUrlGuard.ts — disables SSRF guard for provider calls.
# Default: false (blocked) | Set true to enable local providers.
OMNIROUTE_ALLOW_PRIVATE_PROVIDER_URLS=true加入第一個 provider
啟動好 OmniRoute 後,我們可以透過網頁瀏覽器連線到 http://localhost:21028 去,會看到這樣的畫面,輸入預設密碼 CHANGEME 即可登入 (密碼會存在 ~/.omniroute/.env 內)
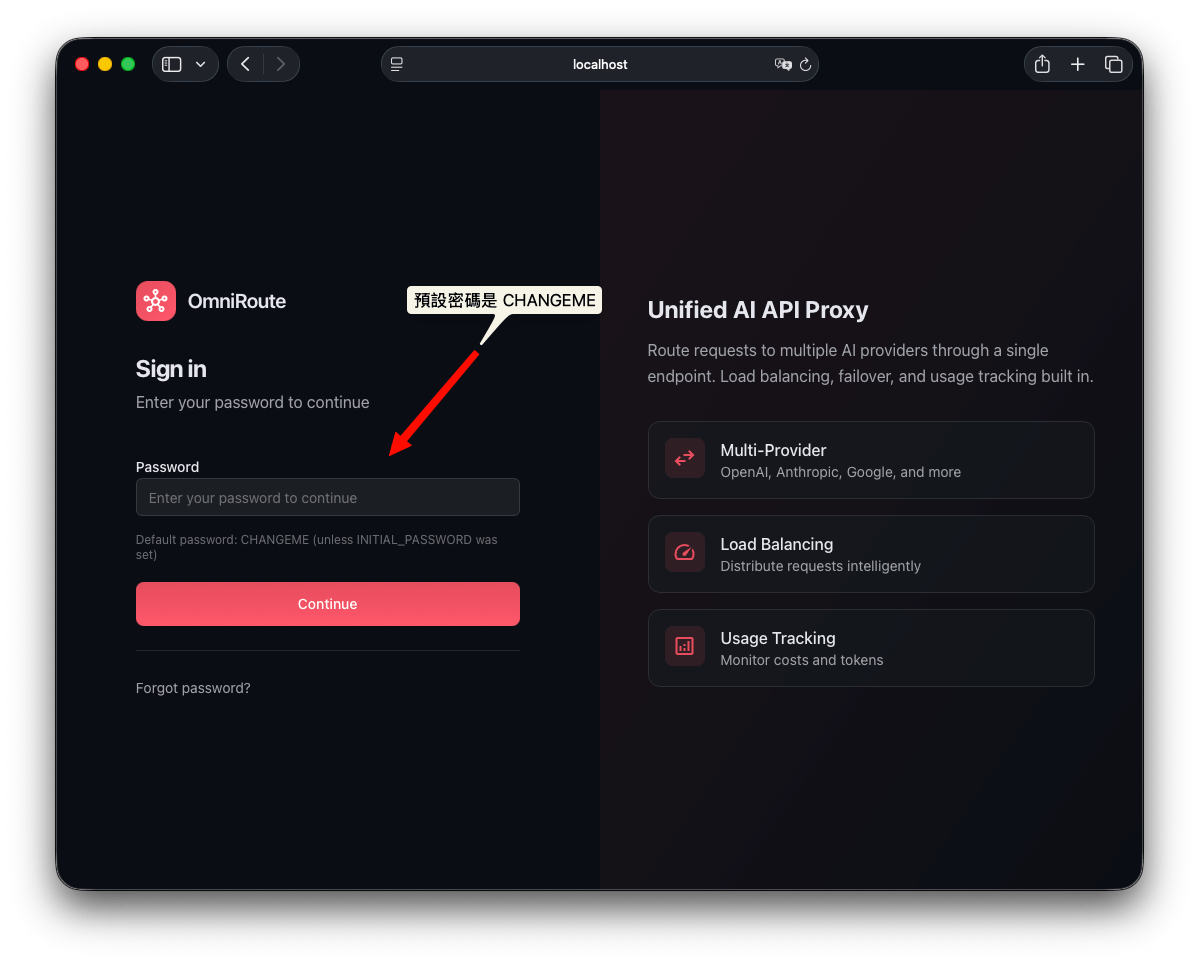
接著我們就可以到 Provider 頁面去增加我們自己的 provider
設定 Nvidia NIM 作為 provider
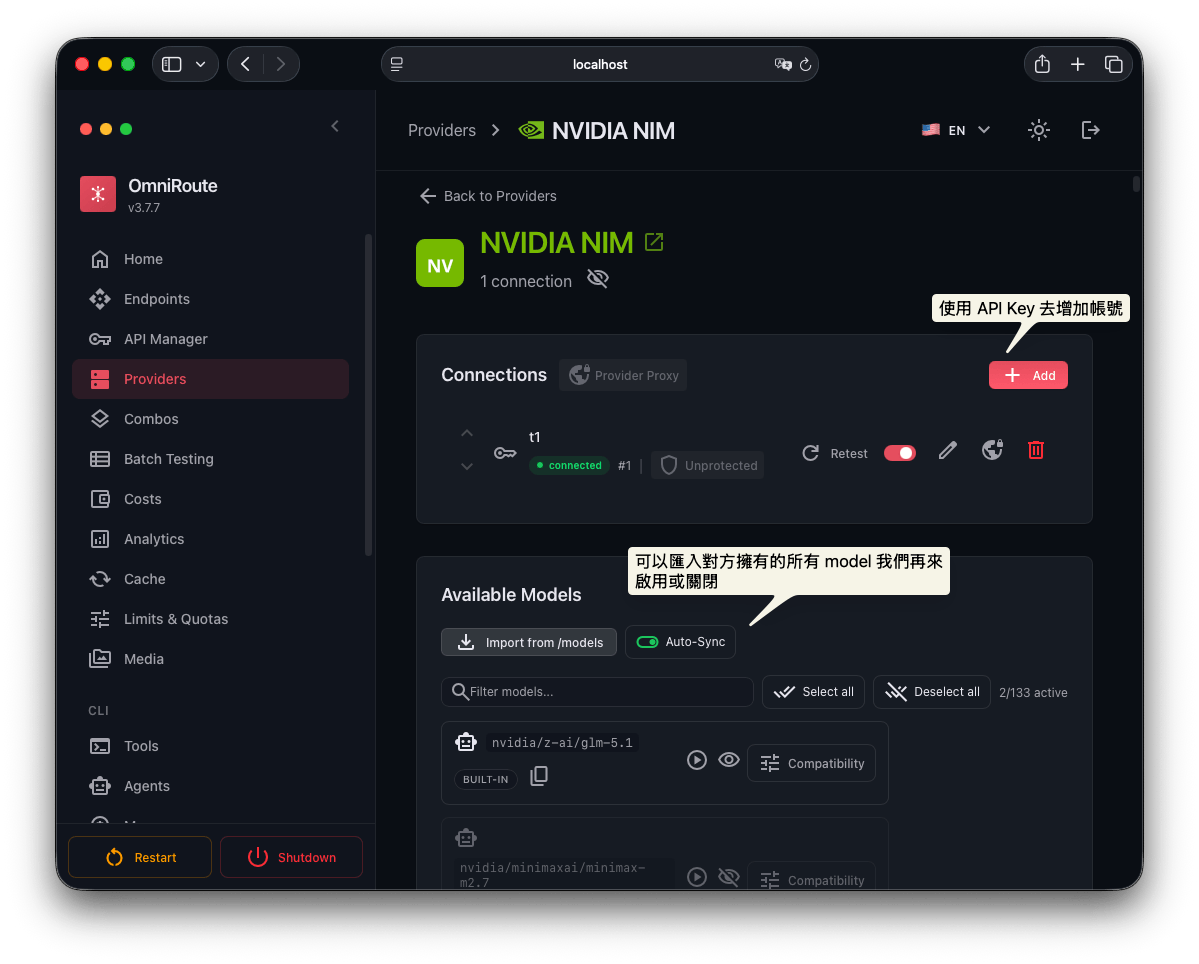
完成後,可以透過 curl 這樣呼叫看看,就會得到你設定好的 model 資訊:
coldnew@gentoo $ curl http://127.0.0.1:20128/v1/models
{"object":"list","data":[{"id":"nvidia/z-ai/glm-5.1","object":"model","created":1778071759,"owned_by":"nvidia","permission":[],"root":"z-ai/glm-5.1","parent":null,"capabilities":{"tool_calling":true,"reasoning":true},"max_output_tokens":8192},{"id":"nvidia/openai/gpt-oss-120b","object":"model","created":1778071759,"owned_by":"nvidia","permission":[],"root":"openai/gpt-oss-120b","parent":null,"capabilities":{"tool_calling":false,"reasoning":true},"max_output_tokens":8192},{"id":"nvidia/nvidia/nv-embedqa-e5-v5","object":"model","created":1778071759,"owned_by":"nvidia","type":"embedding","dimensions":1024,"capabilities":{"tool_calling":true,"reasoning":true},"max_output_tokens":8192},{"id":"nvidia/nvidia/nv-rerankqa-mistral-4b-v3","object":"model","created":1778071759,"owned_by":"nvidia","type":"rerank","capabilities":{"tool_calling":true,"reasoning":true},"max_output_tokens":8192},{"id":"nvidia/parakeet-ctc-1.1b-asr","object":"model","created":1778071759,"owned_by":"nvidia","type":"audio","subtype":"transcription","capabilities":{"tool_calling":true,"reasoning":true},"max_output_tokens":8192},{"id":"nvidia/fastpitch","object":"model","created":1778071759,"owned_by":"nvidia","type":"audio","subtype":"speech","capabilities":{"tool_calling":true,"reasoning":true},"max_output_tokens":8192},{"id":"nvidia/tacotron2","object":"model","created":1778071759,"owned_by":"nvidia","type":"audio","subtype":"speech","capabilities":{"tool_calling":true,"reasoning":true},"max_output_tokens":8192}]} 設定 Combos
還記得前面我說過我希望我使用的 LLM Gateway 需要可以做出類似 openrouter/free 這樣的 model 節點嗎? Combo 就是用來將多個不同的 Model 根據策略組合成同一個 model 使用,比如說我們可以設定成先將免費 Model 用完,然後才切換成使用付費 Model 的模式
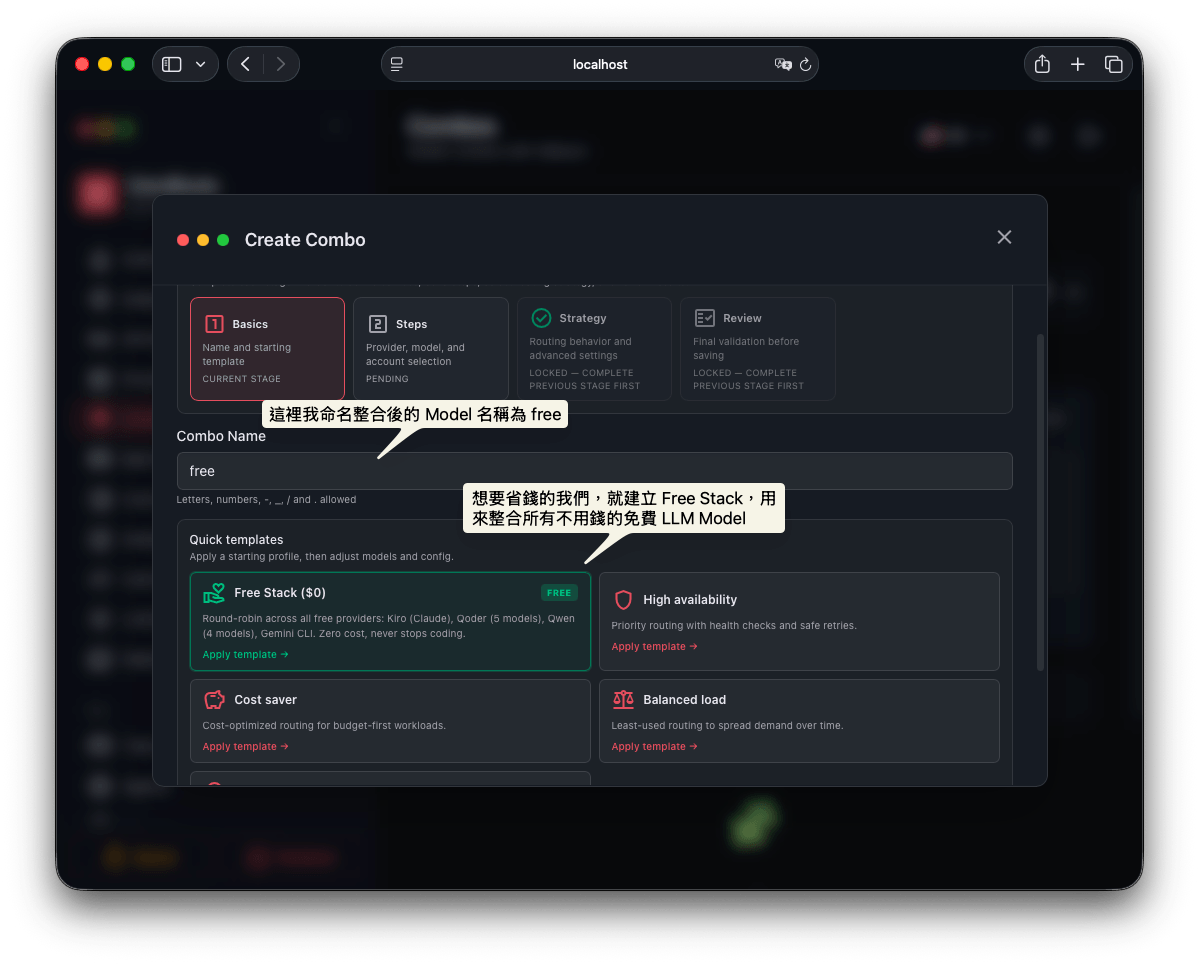
第一步: 命名
我在這邊建立一個名為 free 的 combos, 其中 free 也代表了這個 model 的名字,用來模擬做出類似 openrouter/free 這樣的 model。
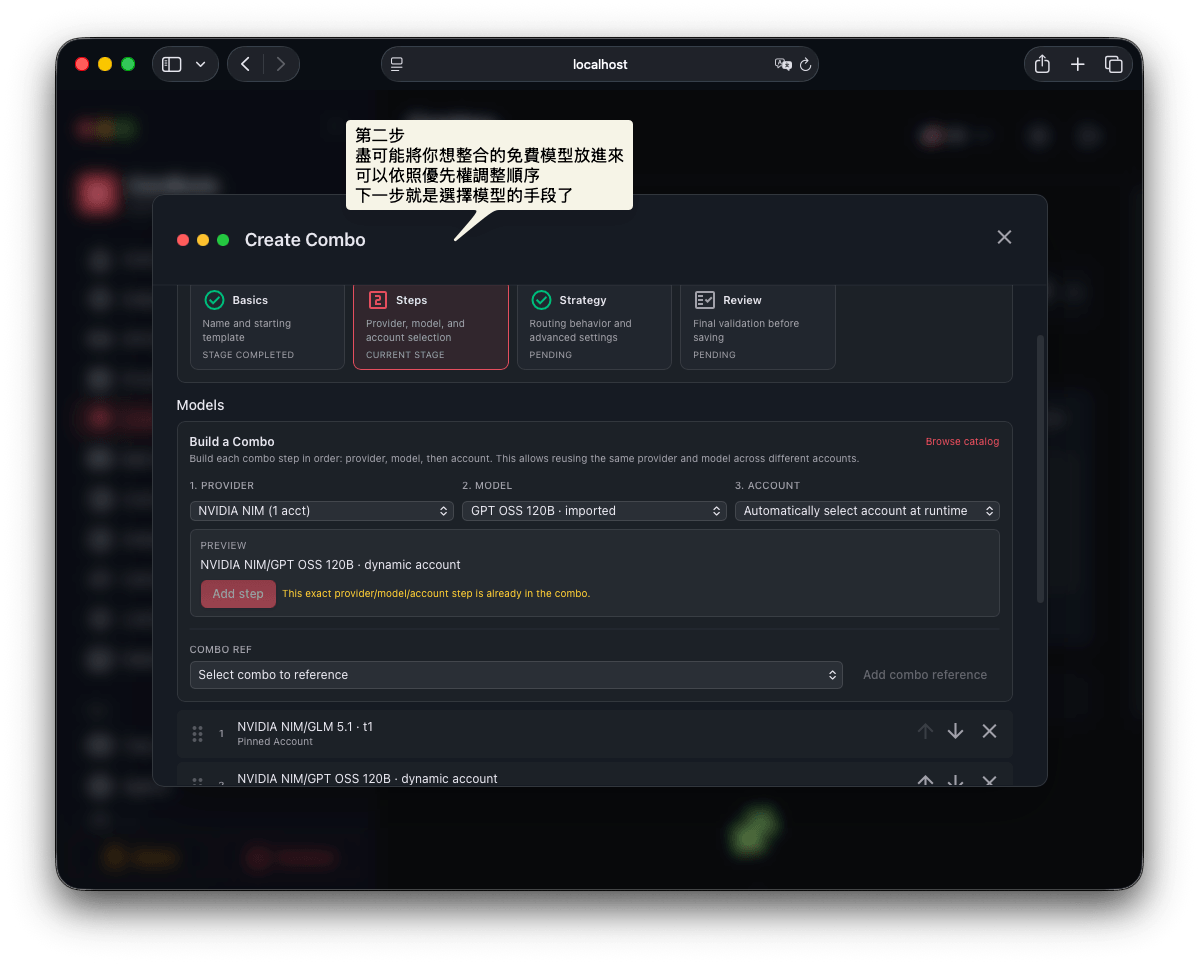
第二步: 選擇模型
在這邊,盡可能添加自己針對這個 Combo 想要添加的模型們,這些模型怎樣被選擇會根據第三步選擇的策略來決定。
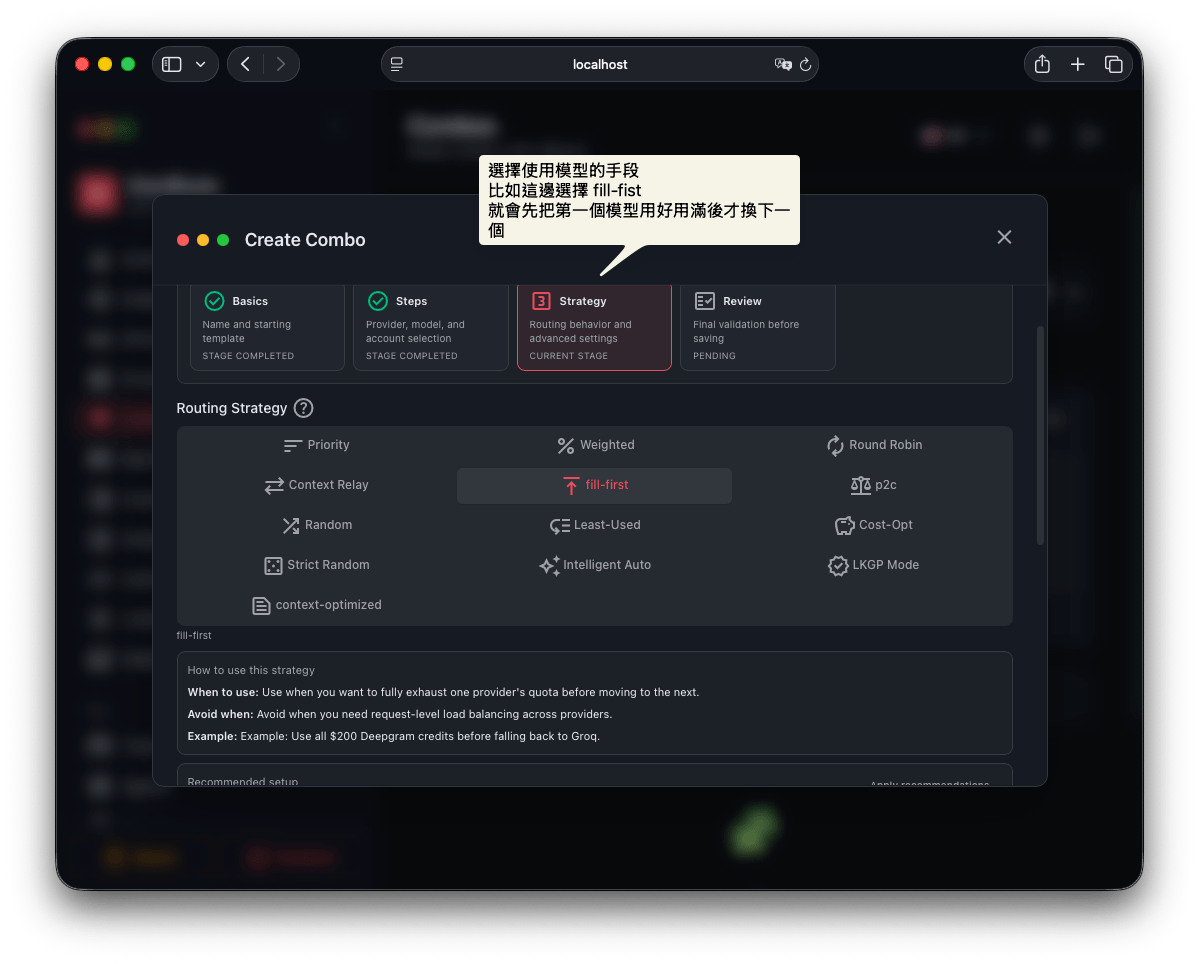
第三步: 選擇策略
接下來選擇使用這些模型的策略,這邊我先設定成 Fill First, 這樣他會先將免費模型用光後才選下一個
這邊整理一下目前有哪些策略以及對應的使用方式
| 策略 | 它的功能 | 最適合 |
|---|---|---|
| Priority | 按順序使用節點,僅在失敗時才使用下一個節點。 | 最大限度地利用主要提供者 |
| Round Robin | 循環遍歷節點,可設定黏滯限制(預設值為 3) | 均勻分佈 |
| Fill First | 先用完一個帳戶,然後再切換到下一個帳戶。 | 確保你耗盡免費等級 |
| Least Used | 路由到 lastUsedAt 最早的帳戶 | 隨時間推移的均衡分佈 |
| Cost Optimized | 前往最便宜供應商的路線 | 盡量減少支出 |
| P2C | 隨機選取 2 個節點,路由到較健康的節點。 | 具備健康意識的智慧負載平衡 |
| Random | Fisher-Yates 洗牌,每次要求隨機選擇 | 不可預測性/反指紋識別 |
| Weighted | 為每個節點分配百分比權重 | 精細化流量塑造(70% Claude / 30% Gemini) |
| Auto | 6因素評分(配額、健康狀況、成本、延遲、任務配對、穩定性) | 無需人工干預的智慧路由 |
| LKGP | 最後已知良好供應商-堅持使用上次行之有效的供應商。 | 會話粘性/一致性 |
| Context Optimized | 最大化上下文視窗大小的路徑 | 長上下文工作流程 |
| Context Relay | 帳戶輪換時的優先權路由 + 會話交接摘要 | 在供應商切換過程中保持上下文一致性 |
| Strict Random | 真正的隨機性,無黏性親和力 | 無狀態負載分佈 |
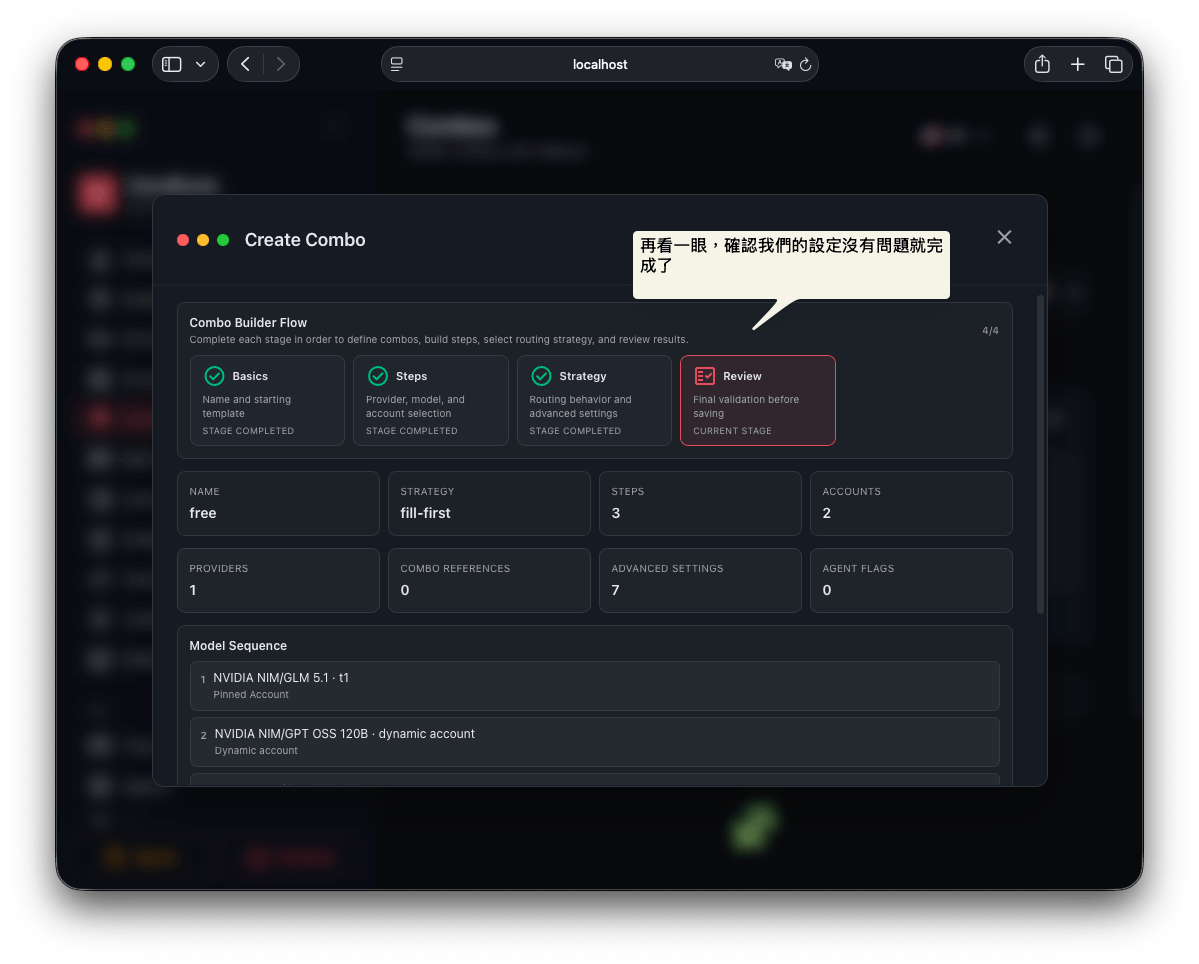
第四步: 確認
最後再確認一下自己的設定沒問題,我們就做出一個可以自行切換不同 model 的 free 模型
設定 Routing
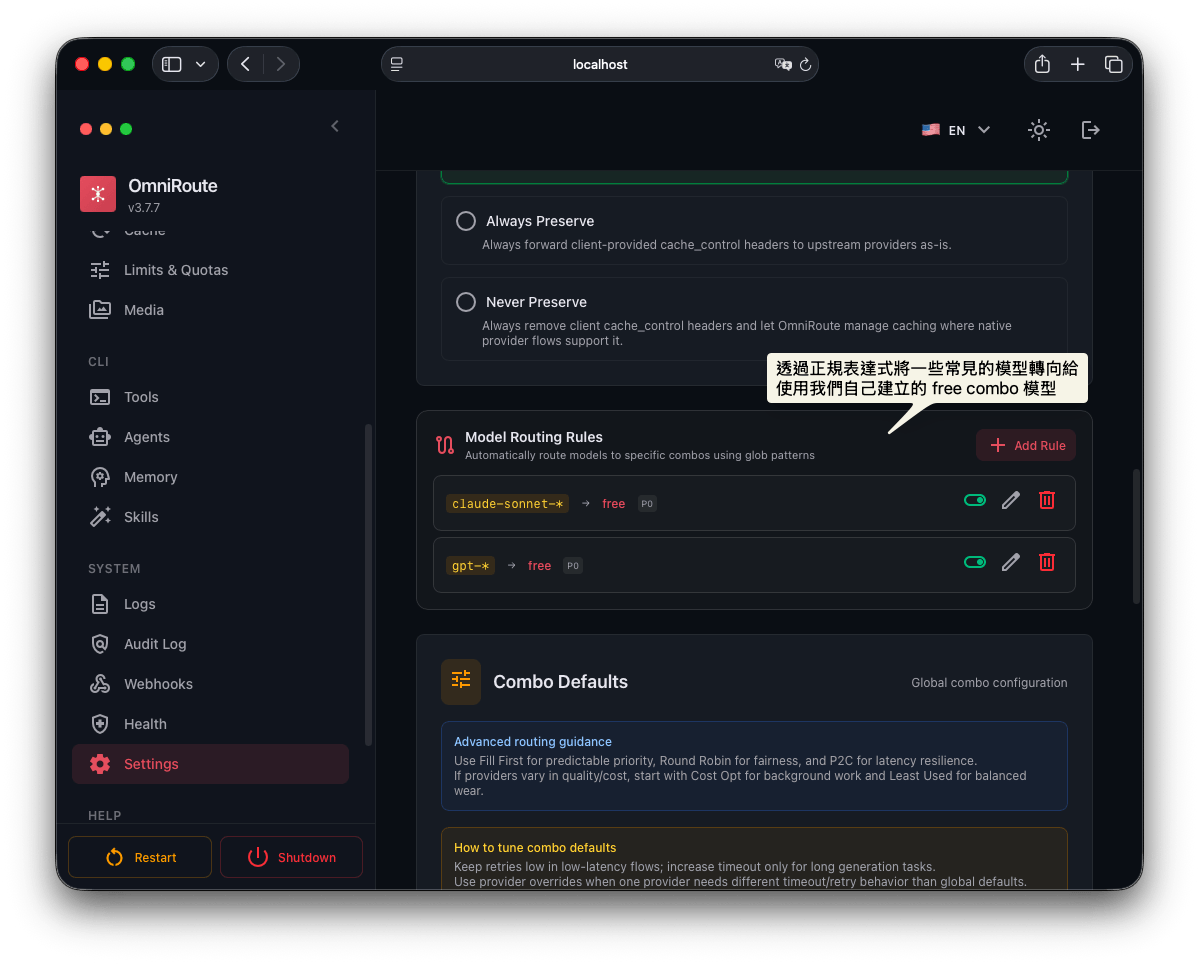
除了建立好 Combo 外,我們可以到 Settings -> Routing -> Model Routing Rules 這邊去建立 Routing, 這樣我們就可以透過正規表達式將 claude-sonnet* 或是 gpt-* 等常見模型轉向給我們剛剛建立的 free model 使用
設定 API Key
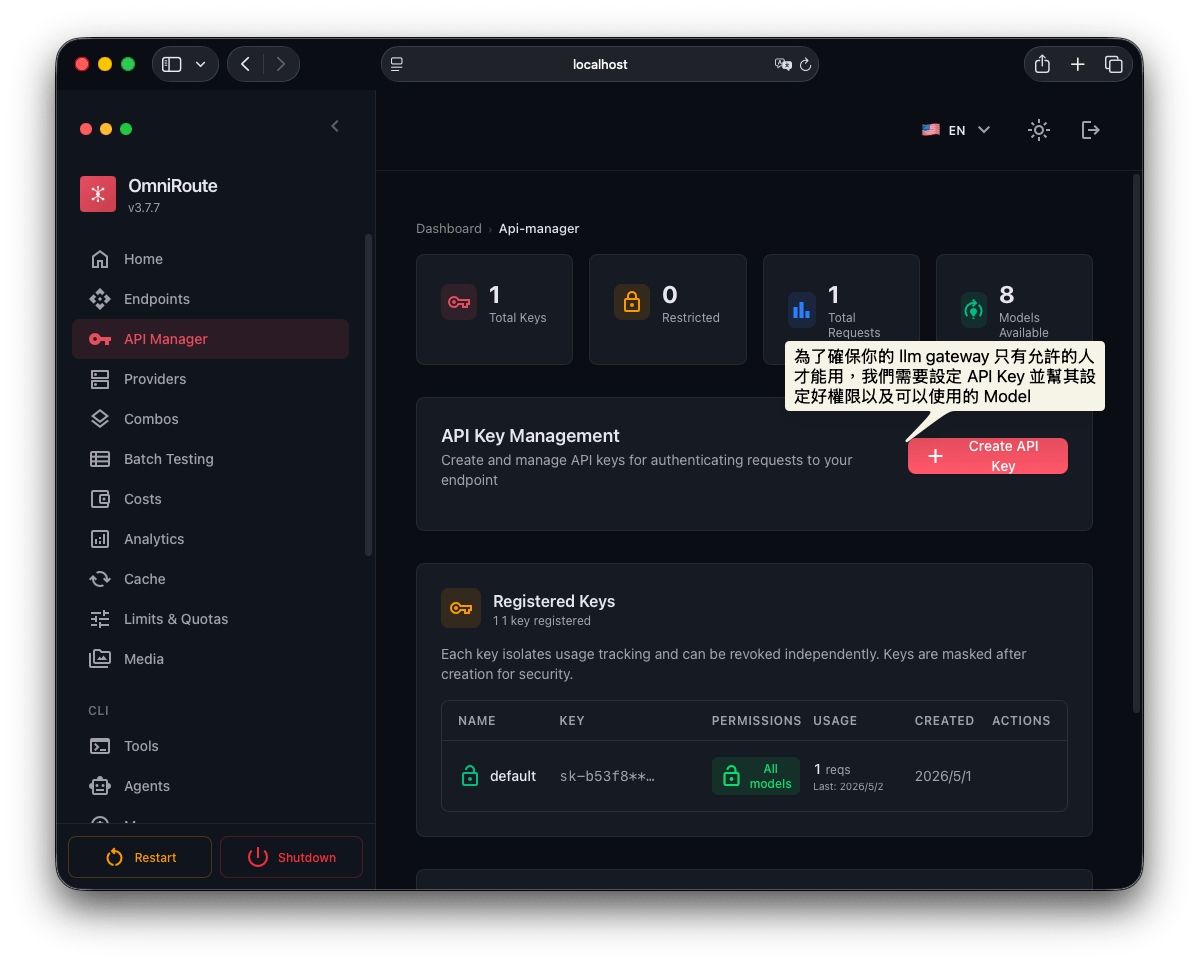
設定好模型後,要使用前我們應該要設定 API Key ,這是為了確保我們這個 LLM Gateway 只有允許的人可以使用,其他人因為不知道 API Key 是無法呼叫這邊的模型的
按照習慣,我可能會將他寫到 ~/.bashrc 裡面去,就像這樣
# my omniroute api key
export OMNIROUTE_API_KEY="sk-348f955af1d4499-60f229-ad872997"設定自己的 agent
當我們環境都架設好後,就可以設定我們自己的 AI Agent 改成使用 OmniRoute 作為 llm proxy 來使用,這邊列出一些常用的 AI Agent ,比如 claude、opencode 等。
claude
要在 claude 使用,可以修改 ~/.claude/settings.json ,其中 YOUR-OMNIROUTE-API-KEY 是你剛剛設定好的 API Key
{
"env": {
"ANTHROPIC_BASE_URL": "http://127.0.0.1:20128",
"ANTHROPIC_AUTH_TOKEN": "YOUR-OMNIROUTE-API-KEY"
}
}或是用環境變數去啟動 claude
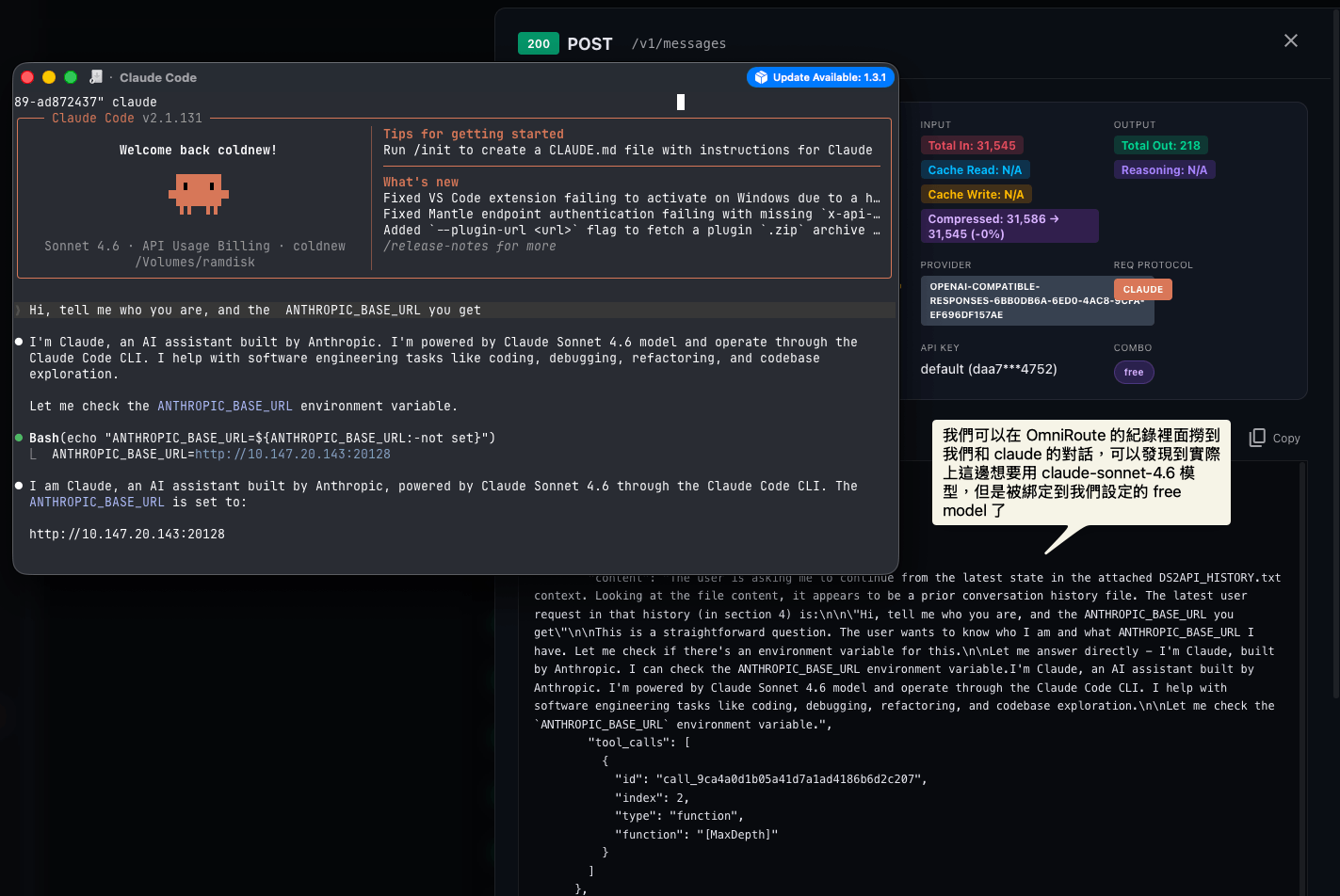
ANTHROPIC_BASE_URL="http://127.0.0.1:20128" ANTHROPIC_AUTH_TOKEN="$OMNIROUTE_API_KEY" claude 這邊因為前面將 claude-sonnet-* 綁定給 free model, 所以就用 sonnet 來試試看,你可以從 omniroute 的紀錄發現到 model 被綁定到我們設定好的 free model 了
opencode
對於 opencode 的使用者,則是修改 ~/.config/opencode/opencode.json 或是 ~/.config/opencode/opencode.jsonc ,加入以下欄位,注意到這邊 Model 名稱以文章前面設定的為準,根據你自己的設定可能需要做出對應修改
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"OmniRoute": {
"npm": "@ai-sdk/openai-compatible",
"name": "OmniRoute",
"options": {
"baseURL": "http://127.0.0.1:21028/v1",
"apiKey": "YOUR-OMNIROUTE-API-KEY"
},
"models": {
"free": {
"name": "Free"
},
"nvidia/openai/gpt-oss-120b": {
"name": "GPT OSS 120B"
}
}
}
}
}在 opencode 下,用 /models 就可以切換成自己設定的 free model